








Getting Started with Data Engineering in Azure: A Beginner’s Guide
Data engineering is a critical field that focuses on the practical application of data collection and analysis. With the rise of cloud computing, platforms like Microsoft Azure have become essential for data engineers. This article blog will help you get started with data engineering in Azure, covering the basics, key tools you’ll need, and common challenges you might face.

So, let's explore Data Engineering in Details!
Data Engineering in Microsoft Azure
Data engineering involves designing, building, and maintaining systems and infrastructure that allow for the collection, storage, and analysis of data. It is a foundational aspect of data science and analytics, ensuring that data is accessible, reliable, and ready for analysis.
Three Types of Data that every Data Engineer has to handle
Before we explain into details, we need to understand that there are three types of data that data engineers have to handle. These include:
Structured Data:
Structured data primarily comes from table-based source systems such as a relational database or from a flat file such as a comma separated (CSV) file. The primary element of a structured file is that the rows and columns are aligned consistently throughout the file.

Figure: Structured Data, Image courtesy of Microsoft Azure
Semi-Structured Data:
Semi-structured data is data such as JavaScript object notation (JSON) files, which may require flattening prior to loading into your source system. When flattened, this data doesn't have to fit neatly into a table structure.

Figure: Semi-Structured Data, Image courtesy of Microsoft Azure
Unstructured Data:
Unstructured data includes data stored as key-value pairs that don't adhere to standard relational models and Other types of unstructured data that are commonly used include portable data format (PDF), word processor documents, and images.

Figure: Unstructured Data, Image courtesy of Microsoft Azure
Operations you need to handle as a Azure Data Engineer
From the Azure Data Engineer's perspective, you might need to handle the following tasks as below. I have attached some of the data operations as follows:
Data Integration as part of Azure Data Engineering
Data integration refers to the process of combining and harmonizing data from multiple sources into a unified, coherent format. This unified data can then be used for various analytical, operational, and decision-making purposes.
It involves several steps, including identifying data sources, extracting data, mapping data elements, ensuring data quality, transforming data into a consistent format, and loading it into a data warehouse or other destination for analysis. Essentially, data integration allows businesses to gain a more valuable and unified view of their data, enabling faster and better decision-making.
Figure: Data Integratoin, Image courtesy of Microsoft Azure
Data Transformation as part of Azure Data Engineering
Data Transformation involves combining operational data from various sources into a unified format. This process includes extracting, transforming, and loading data (ETL or ELT) to support downstream analytics. The goal is to create a coherent view of data for better decision-making
Figure: Data Transformation, Image courtesy of Microsoft Azure
Data Consolidation as part of Azure Data Engineering
We need to understand that data consolidation refers to combining the data which has been gathered already from multiple sources into a consistent structure. In this stage, we have to extract data from operational systems, conduct transformation and finally load into analytical stores such as a data lake or data warehouse.
Figure: Data Consolidation, Image courtesy of Microsoft Azure
Key Critical Data Engineering Concepts you must know
Here are some of the basic fundamental data engineering concepts in Azure, if you want to become Azure Data Engineer in future. I have attached some as follows:
What are Operational and analytical data?
Operational data refers to transactional data that is generated and stored by applications. In fact, they might be kept in either a relational or non-relational database.
However, Analytical data refers to data that has been optimized for analysis and reporting. It is usually stored in a data warehouse.
Therefore, as a data engineer, you will have to design, implement, and manage solutions that uses both operational and analytical data sources, as well as integrating and loading it into analytical data stores.
Figure: Operational and Analytical Data, Image courtesy of Microsoft Azure
Understanding about Streaming Data!
Streaming data are actually data values in real-time such as football live streaming, stock trading data etc. These may include internet-of-things (IoT) devices and social media feeds.
Therefore, Azure data engineering solutions have to be able to capture real-time data streaming, as well as ingesting into Azure analytical systems.

Figure: Data Pipelines, Image courtesy of Microsoft Azure
Understanding about Data Pipelines!
Azure Data Engineering Systems can conduct tasks based on task and inputs from data pipelines as well. We called it, CI / CD, Continuous Integration and Continuous Deployment in Azure pipelines. These data pipelines are often used to transfer, transform data, as well as conduct ETL solutions managed by Azure Data Engineers.

Figure: Streaming Data, Image courtesy of Microsoft Azure
Understanding about Data lakes!
Another important concept in Azure Data Engineering is the Data Lake. In fact, it is a storage area that can store extensive amounts of data in raw formats. In fact, they can even handle up to terabytes or petabytes of data storage. All these data sources can be structured, semi-structured, or unstructured.
One of the concept in Azure data lake is to be able to store everything in its original, untransformed state. This approach differs from a traditional data warehouse, which transforms and processes the data at the time of ingestion.

Figure: Data lakes, Image courtesy of Microsoft Azure
Understanding about Data warehouses!
Another concept similar with the previous Data lake, is the Data warehouse. For new learners, they might thought these two can be same, but actually they are different.
While the previous Data lakes store data in a raw format in original state, this Azure Data warehouse acts as a centralized storage area, which store integrated from multiple sources. Data are mainly stored in relational tables which are organized into schemas for better optimization performance for analytical purposes!
Yep!, data engineers are responsible for designing and implementing relational data warehouses, and managing regular data loads into tables.
Figure: Data warehouses, Image courtesy of Microsoft Azure
Understanding about Apache Spark!
The final one you should know as a Data Engineer is the Apache Spark. In fact, it is a 3rd party framework, which utilizes in-memory processing and distribute file storage. These Apache Spark is mainly designed for big data solutions.
Thus, as a Azure Data Engineer, you have to understand and proficient in Apache Spark coding, so that you could process big data in Azure Data Lake, which then later to be prepared for data modeling and analysis.

Figure: Apache Spark, Image courtesy of Microsoft Azure
Essential Azure Services for your Data Engineering in Azure
Azure Data Factory
Azure Data Factory (ADF) is a cloud-based data integration service that allows you to create, schedule, and orchestrate data workflows. It supports a wide range of data sources and can be used to move data between on-premises and cloud environments.
Key Features:
- Data movement and transformation
- Pipeline orchestration
- Integration with other Azure services
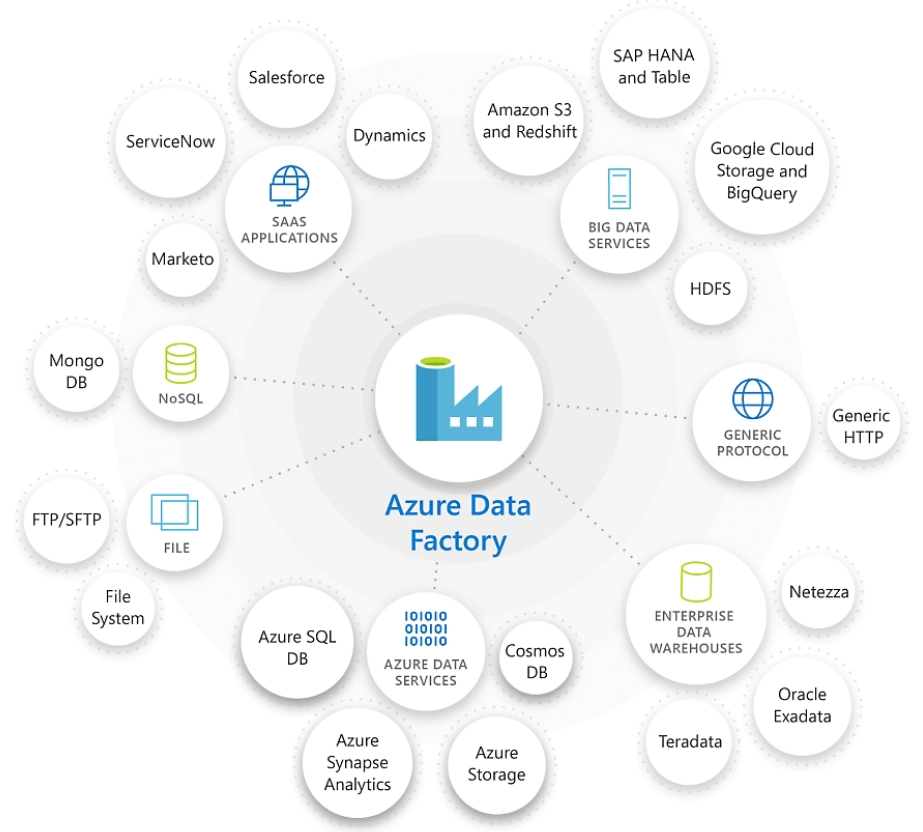
Figure: Azure Data Factory, Image courtesy of Microsoft Azure
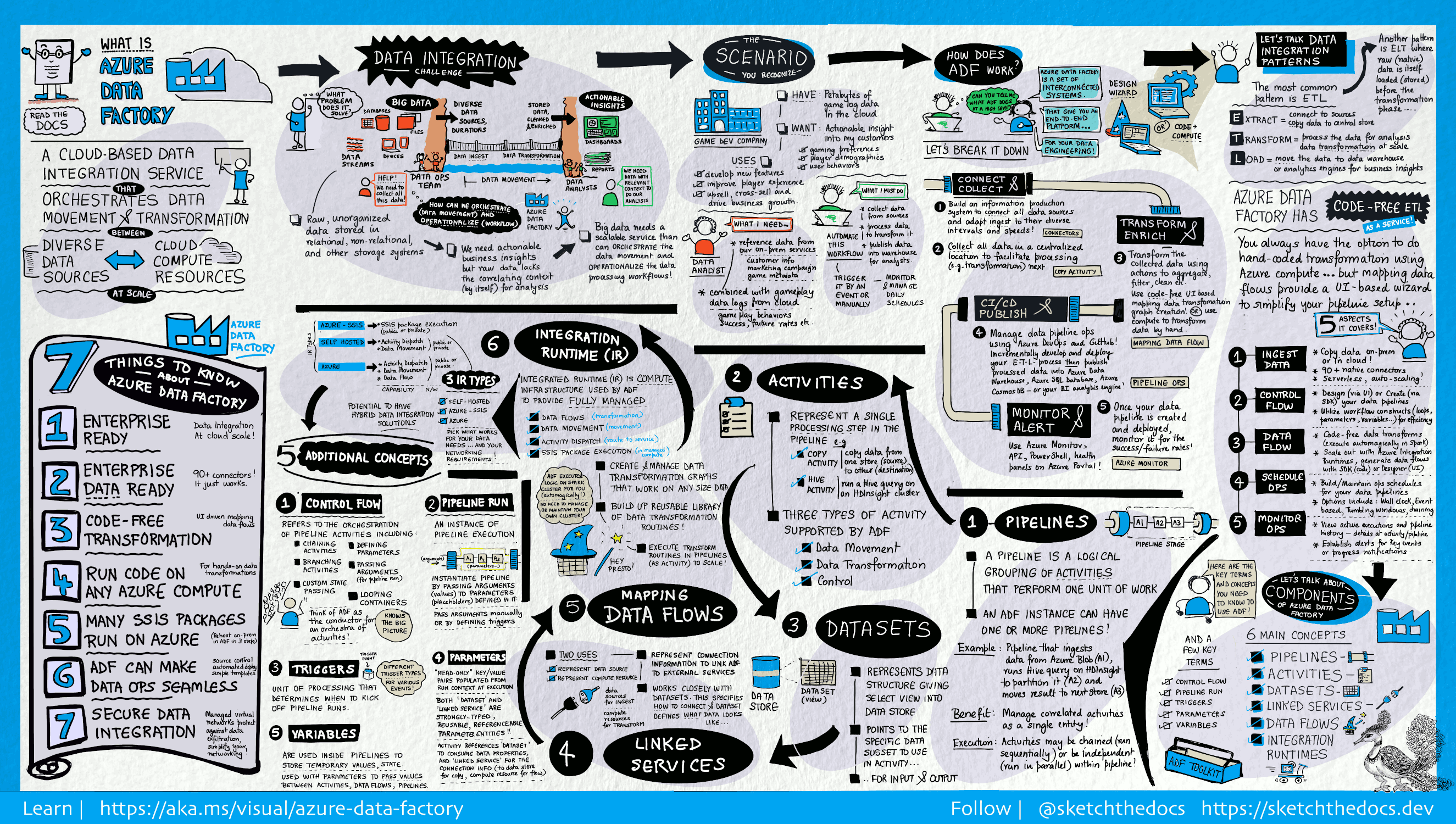
Figure: Azure Data Factory Visual Guide, Image courtesy of Microsoft Azure
Azure Synapse Analytics
Azure Synapse Analytics is an integrated analytics service that combines big data and data warehousing. It allows you to query data on your terms, using either serverless or provisioned resources at scale.
Key Features:
- Unified analytics experience
- Integrated with Apache Spark and SQL
- Real-time data processing
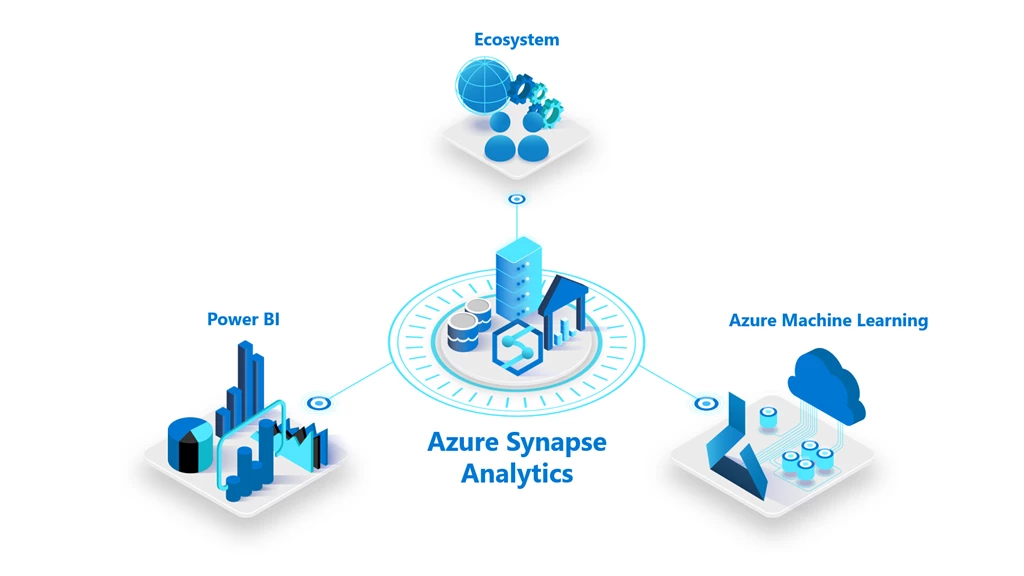
Figure: Azure Synapse Analytics, Image courtesy of Microsoft Azure
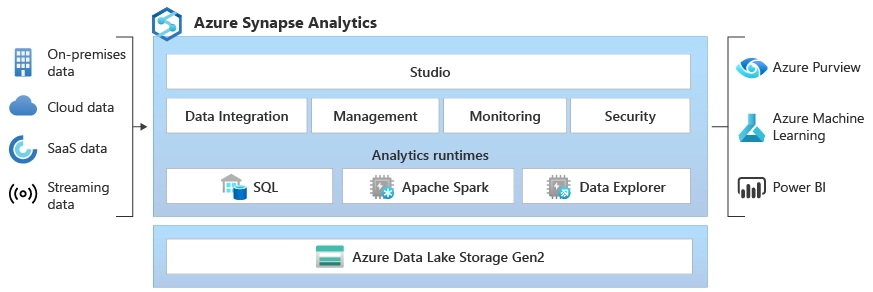
Figure: Azure Synapse Analytics Architecture, Image courtesy of Microsoft Azure
Azure Databricks
Azure Databricks is an Apache Spark-based analytics platform optimized for Azure. It provides a collaborative environment for data engineers, data scientists, and business analysts to work together.
Key Features:
- High-performance analytics
- Collaborative notebooks
- Integration with Azure Machine Learning
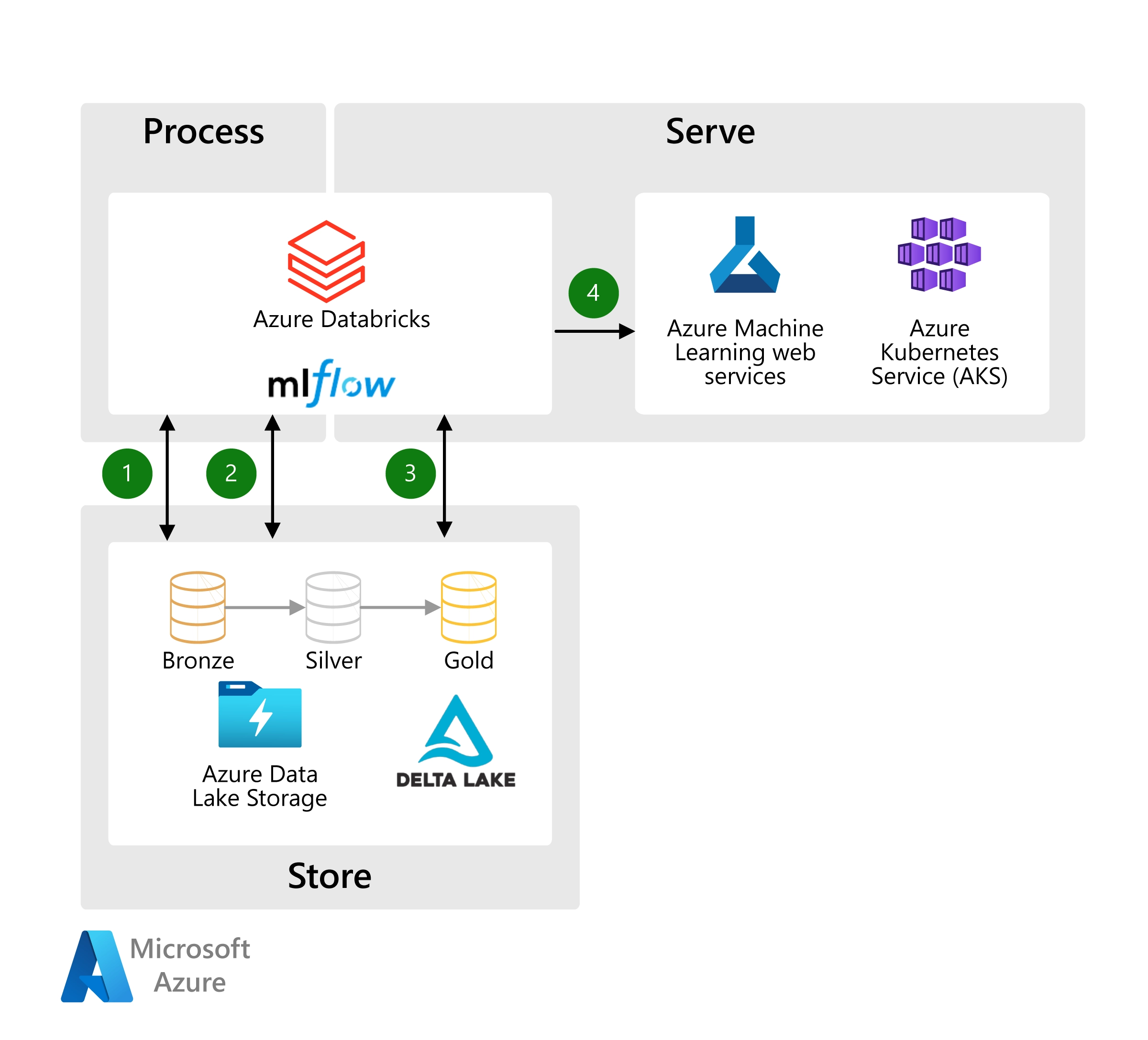
Figure: Azure Databricks, Image courtesy of Microsoft Azure
Azure Stream Analytics
Azure Stream Analytics is a real-time analytics service designed to process and analyze streaming data from various sources like IoT devices, social media, and applications.
Key Features:
- Real-time data processing
- Scalable and reliable
- Easy integration with other Azure services
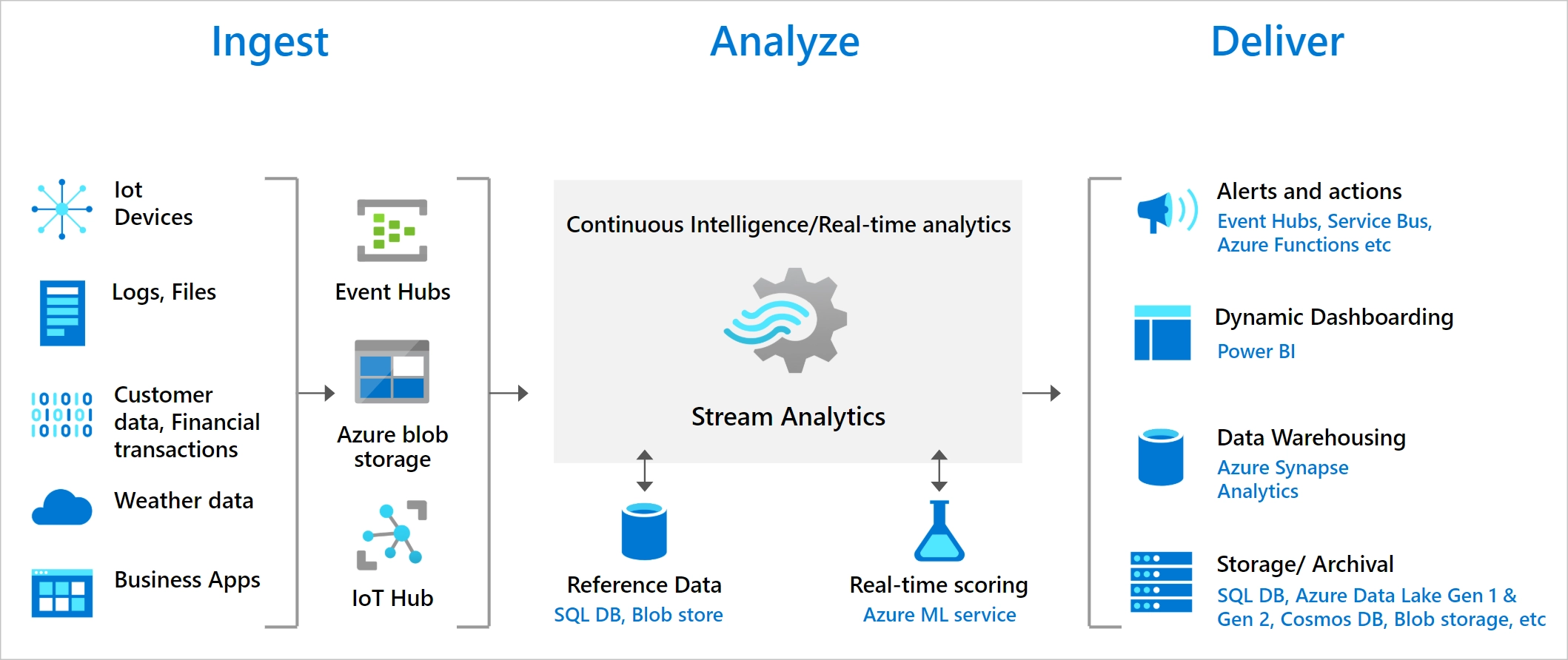
Figure: Stream Analytics Pipeline, Image courtesy of Microsoft Azure
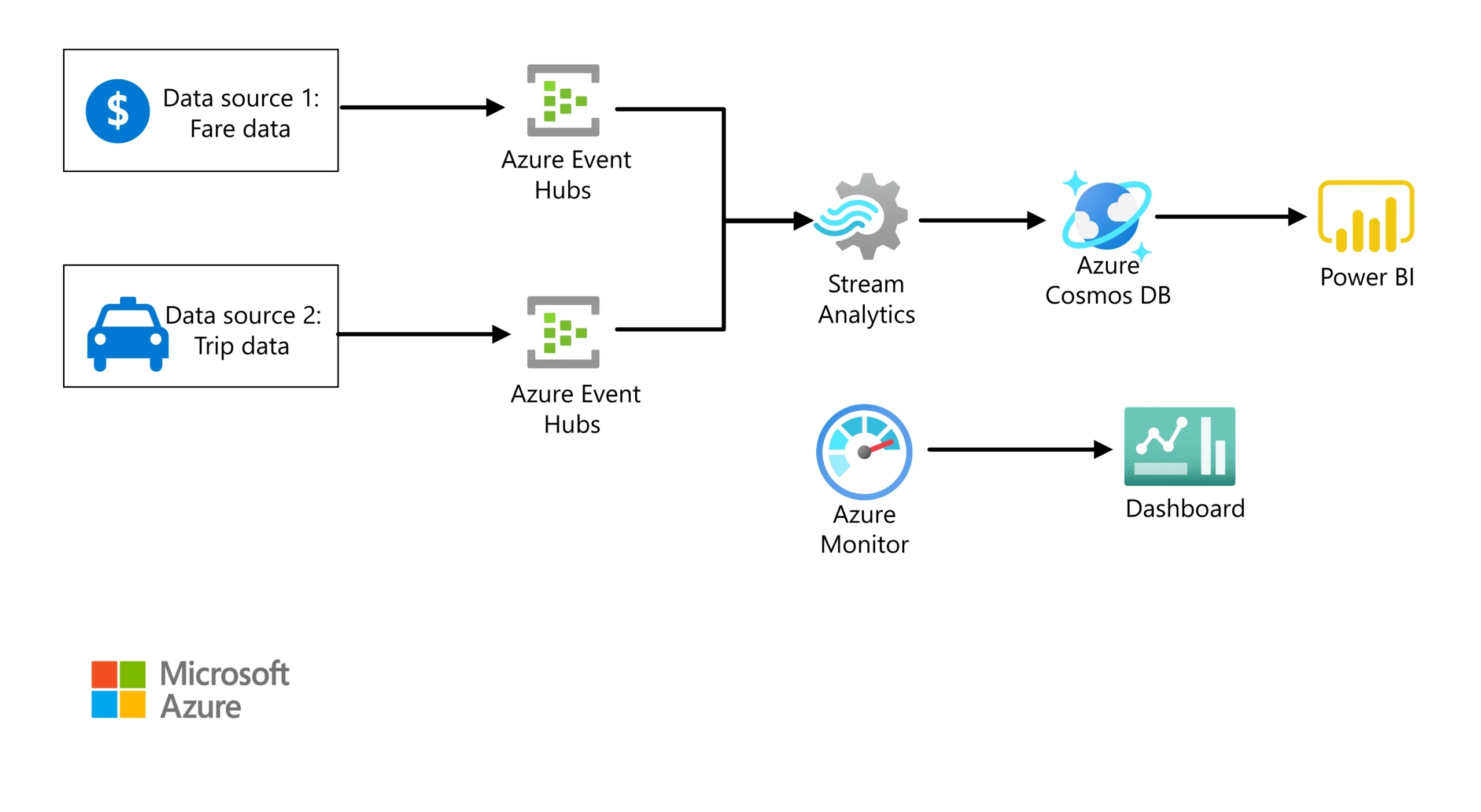
Figure: Stream Processing in Stream Analytics, Image courtesy of Microsoft Azure
Azure Data Lake Storage
Azure Data Lake Storage is a scalable and secure data lake for high-performance analytics workloads. It allows you to store data of any size, shape, and speed.
Key Features:
- Unlimited storage
- High throughput and low latency
- Integration with Azure analytics services
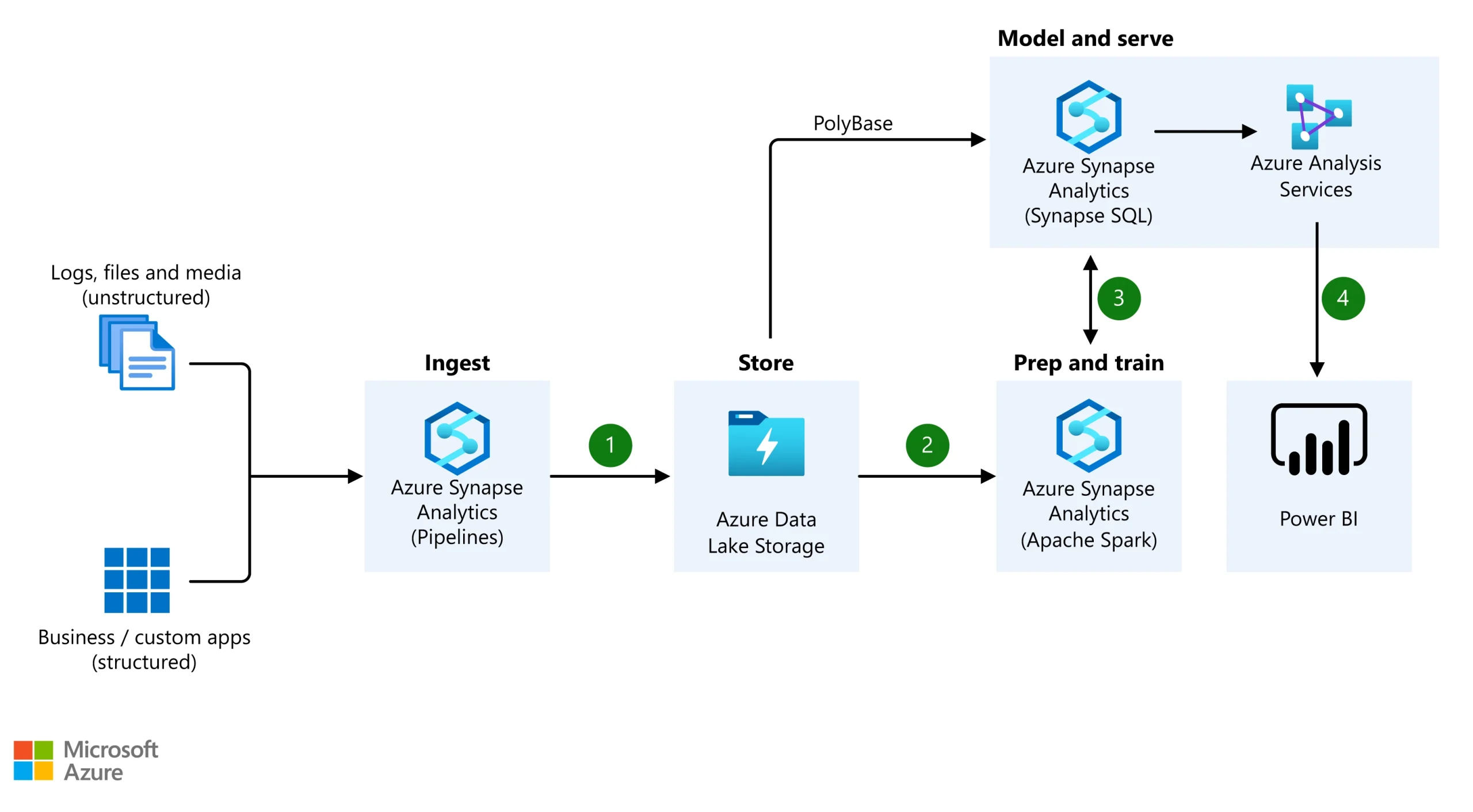
Figure: Azure Data Lake Storage in Enterprise Warehouse Architecture, Image courtesy of Microsoft Azure
Figure: Azure Data Lake Storage Gen2, Image courtesy of Microsoft Azure
Common Data Engineering Challenges in Azure
Data Ingestion Challenges
Challenge: Data ingestion involves collecting and importing data from various sources into a storage system. The main issue here is the variety of data formats and structures, which require transformation before further processing.
Solution: Use tools like Azure Data Factory to automate and streamline the data ingestion process. It supports a wide range of data sources and formats, making it easier to handle diverse data.
Data Integration Challenges
Challenge: Integrating data from multiple sources can be complex, especially when dealing with different data formats, schemas, and structures. Ensuring that data is consistent and accurate across all sources is crucial.
Solution: Implement a robust ETL (Extract, Transform, Load) process using Azure Data Factory. This helps in transforming and integrating data from various sources into a unified format.
Data Storage Challenges
Challenge: Storing large volumes of data efficiently and cost-effectively can be challenging. Ensuring that the storage solution can scale with the growing data volume is essential.
Solution: Utilize Azure Data Lake Storage for scalable and secure data storage. It offers high throughput and low latency, making it suitable for large-scale data storage needs.
Data Processing Challenges
Challenge: Processing large datasets quickly and efficiently is a common challenge. This includes batch processing, real-time processing, and handling complex data transformations.
Solution: Leverage Azure Databricks for high-performance data processing. Its integration with Apache Spark allows for efficient batch and real-time data processing.
Data Quality and Governance Challenges
Challenge: Ensuring data quality and governance is critical for reliable data analysis. This includes dealing with missing data, duplicates, and maintaining data integrity.
Solution: Implement data validation and cleansing processes using Azure Data Factory. Additionally, use Azure Purview for data governance to maintain data quality and compliance.
Data Pipeline Orchestration Challenges
Challenge: Orchestrating complex data pipelines and workflows can be difficult, especially when dealing with dependencies and scheduling.
Solution: Use Azure Data Factory to design, schedule, and manage data pipelines. It provides a visual interface for creating and monitoring workflows, making it easier to manage complex data pipelines.
Data Security Challenges
Challenge: Protecting sensitive data from unauthorized access and ensuring compliance with data protection regulations is a major concern.
Solution: Implement Azure’s security features, such as encryption, access controls, and monitoring. Use Azure Key Vault to manage and secure sensitive information like keys and passwords.
Monitoring and Maintenance Challenges
Challenge: Monitoring data pipelines and maintaining the infrastructure to ensure smooth operation can be resource-intensive.
Solution: Use Azure Monitor and Azure Log Analytics to monitor the performance and health of your data pipelines. Set up alerts and automated responses to quickly address any issues.
Best Practices for Data Engineering in Azure
-
Automate Workflows: Use Azure Data Factory to automate data movement and transformation.
-
Optimize Costs: Monitor and manage your resource usage to keep costs under control.
-
Ensure Security: Implement Azure’s security features to protect your data.
-
Stay Updated: Keep up with the latest Azure updates and features to leverage new capabilities.
CONCLUSION
Getting started with data engineering in Azure can seem daunting, but with the right tools and guidance, it becomes manageable and rewarding. Azure provides a robust platform with a wide range of services to support your data engineering needs. By following this guide and being aware of common challenges, you’ll be well on your way to building efficient and scalable data solutions in Azure.